8 tools compared on what actually matters — not features, but whether you can trust the matches and who does the work when things break.
We've spent 20+ years building managed data operations for ecommerce. Product matching grew out of that work — clients needed not just raw competitor data, but matched product sets they could trust for pricing decisions.
We evaluated 8 product matching tools and services against real G2 and Capterra reviews, published case studies, and our own operational experience. Here's where each one works, where it breaks, and who it's actually built for.
Why Your Competitor Prices Are Only as Good as Your Matches
You have a pricing meeting in two hours. You open your competitor data. One product shows your competitor at $149 — but when you check their site, it's $89.
The tool matched the wrong product. A similar name, a similar category, even a similar image — but a different size variant. The system scored it at 92% confidence. The dashboard showed a green checkmark.
Now you don't trust any of the other 4,000 rows.
This is the product matching problem. Before you can compare prices, track MAP violations, or analyze assortment gaps, you need to connect your products to the same products on competitor sites. Get the match wrong, and every analysis built on top of it is wrong too.
At 95% matching accuracy on a 10,000-SKU catalog, 500 products have wrong competitor data. Every delivery cycle.
Five hundred. Every cycle.
If you can't trust the match, you can't trust the price.
That's not a hypothetical. It's arithmetic. And it applies to every tool that claims 95% accuracy — which is most of them.
We researched 8 product matching tools and services — self-service tools, enterprise platforms, and managed services. We reviewed 300+ public user reviews and cross-checked them against vendor documentation, published case studies, and what we see in our own matching operations every day.
We built a three-question framework that narrows these 8 options to the 2–3 that fit your situation — because the best option depends on your catalog, your team, and your operating model.
This is what we found.
How Product Matching Actually Works (And Where It Breaks)
Product matching connects your products to the same or similar products on competitor sites. Once connected, you can compare prices, track changes, and act on intelligence — but only if the match is correct.
Three matching approaches exist, and understanding the differences saves you from buying the wrong solution:
Identifier-based matching uses GTIN, UPC, or EAN barcodes. Fast and accurate when identifiers exist on both sides. The problem: fashion, private label, own-brand, and white-label products often share no identifiers with competitor listings. If your catalog is primarily non-barcoded, this approach leaves most of your products unmatched.
AI/ML-based matching uses text similarity, product attributes, and sometimes images to find matches without identifiers. More flexible — but here's the danger most buyers miss. The worst outcome isn't a match that fails. It's a match that succeeds confidently — but matched the wrong product.
A luxury retailer sells the "Oskan Moon suede shoulder bag" in brown at $1,850. The matching system returns "Oskan Soft Zip shoulder bag" in black at $1,450 — scored at 72% confidence. Same brand, same product family, similar price. But a different bag entirely: different silhouette, different closure, different material finish. At 72%, a reviewer might catch it. Push that score to 88% — same model, same color family, slightly different size — and it sails through. The dashboard shows a green checkmark. Your team adjusts strategy against the wrong product.
The confident wrong match is the most expensive kind — it's invisible until it corrupts a decision.
Hybrid matching combines AI with human review on edge cases. The question that determines everything: who does the human review — the vendor's team or yours? That single answer is the difference between buying a tool and buying a service.
Every system produces one of three match types: exact match (same product, pricing-ready), similar match (comparable but not identical — useful for assortment analysis, misleading for price comparison), and not a match. The "similar" category is where wrong matches hide. A tool that forces similar items into the exact-match bucket produces data that looks clean but corrupts every decision built on it.
Here's the part most tools skip entirely. Some systems add a third matching phase: deep matching using image comparison on the final candidate shortlist. Text alone can't reliably resolve "Nike Air Max 90 — White/Black" across Men's, Women's, and Kids versions.
The names are near-identical. The products are visually unmistakable. Without image comparison, the system picks whichever variant scores highest on text — and it's often wrong.
In a recent deployment — matching over 2,000 fashion products across two catalogs with no shared identifiers — we caught 644 matches scoring 85–95% confidence that would have passed any text-only system. Wrong size variant, wrong colorway, different model year, different bundle composition. All 644 had passed text matching. Deep matching with image comparison caught every one.
644 confident wrong matches in a single pipeline run. That's not an edge case — that's what happens at scale when text-only matching meets real catalog complexity.
One thing to understand before comparing tools: for most solutions in this space, product matching isn't the core product. Prisync is a price tracker — matching is a barcode lookup to get you into the dashboard. Priceva is a repricing engine — matching is the setup step. Competera is a full pricing optimization platform — matching is one module among many. When matching is a feature inside a bigger product, it gets the attention of a feature, not a product. The tools where matching quality holds up under catalog complexity are the ones that treat matching as a standalone capability worth investing in — not an afterthought on the way to a dashboard.
For complex catalogs — fashion, luxury, private label, products with heavy variant structures — there's a dimension that determines matching quality more than any algorithm: whether the system builds matching rules per catalog pair.
Matching a fashion brand against a multi-brand retailer requires different logic than matching an electronics catalog against a marketplace. The signals that determine whether two products are the same — and where those signals sit in the product data — differ from one pair to the next.
A system that applies one universal rule set works for simple, barcoded catalogs. But for catalogs with real complexity, universal rules produce false positives in categories that need strict logic and false negatives in categories that need flexible ones.
For complex catalogs, one set of rules for everything is how you get "95% accuracy" that's actually 95% on easy products and 60% on the ones that matter most.
How do you test for all of this — matching approach, deep matching, pair-specific rules — in a vendor evaluation? We've distilled it into five demo questions in the evaluation section below.
3 Questions That Narrow 8 Tools to the 2–3 That Fit
Most comparison articles list tools by rating and move on. That gives you a longer list to evaluate blindly — not a shorter one.
These three questions work differently. Apply them in order. Each one eliminates options that don't fit your situation and surfaces the dimensions that actually determine whether matching works for your team.
Question 1: Do Your Products Have Universal Identifiers?
This is the first filter. If your products have GTINs, UPCs, or EANs that competitors also list, most tools in this comparison will work.
If they don't — and for fashion, private label, own-brand, and white-label retailers, they often don't — you immediately eliminate tools that depend on barcodes and need to prioritize multi-signal matching.
Prisync relies entirely on barcodes for automatic matching. A G2 user explicitly asked for name- and image-based matching — confirming it's not available. Without barcodes, you add competitor URLs one product at a time. And maintain every URL indefinitely.
Competera claims non-GTIN matching, but a Capterra user reports that "apparently easy-to-identify items cannot be found despite several runs." Five independent reviewers flag matching quality issues.
Intelligence Node is architecturally built for non-GTIN categories — Computer Vision, NLP, and documented "soft category" matching for bed linen, perfume, and fashion across a 400K+ SKU deployment.
In our own non-GTIN deployments, the critical capability isn't just matching — it's knowing when not to match. Near-matches that look right to text-only systems get correctly rejected rather than forced into the exact set. That distinction disappears when a tool depends on barcodes it doesn't have.
The takeaway: Barcoded catalog? Most tools in this comparison can handle it. Non-barcoded? For many buyers, this filter will eliminate several options immediately.
Question 2: Who Does the Matching Work — Your Team or the Vendor?
This is the dimension most comparison articles skip entirely. And it's the one that determines your actual cost.
| Model | Who does what | Your weekly effort |
|---|---|---|
| Self-service | You configure, run, and maintain matching | 5–10+ hrs/week |
| Enterprise platform | AI matches, you verify and maintain in dashboard | 2–5 hrs/week |
| Managed service | Vendor handles matching, QA, and delivery — you review output | 30 min–1 hr/week |
Multiple Prisync users on G2 describe the reality: URL maintenance, catching broken links, verifying data accuracy. One puts it directly: "Manual effort needed to address missing URLs detracts from overall efficiency." Users have requested dead-link detection since 2019. Still not standard in 2026.
Even enterprise platforms transfer work back when matching breaks. A Competera user on Capterra describes "a great deal of manual effort" when automated mapping doesn't perform as expected.
Now do the math. If your team spends 8 hours a week maintaining a $99/month tool at $65/hour fully loaded, the actual monthly cost is approximately $2,200. A managed service where your team spends 30 minutes reviewing delivered output may carry a higher invoice — but a lower total cost.
Our managed model absorbs the entire operational layer — setup, matching, QA, delivery, and ongoing maintenance. When competitor catalogs change — new products added, variants restructured, SKUs discontinued — the match set needs updating. In a self-service tool, that's your team's job. In a managed service, it's ours.
The real cost isn't the subscription. It's the team time nobody budgets for.
That ongoing match maintenance is what makes the model work. Not just "we do matching once," but we keep your matched product set current without your team touching it.
Question 3: Can You See WHY Each Match Was Made?
This question eliminates most options instantly.
In our review, six of the eight tools tell you THAT a match was made. Only two clearly surface buyer-facing match reasoning.
That distinction sounds academic until the first time you need to defend a pricing decision in a meeting. Or the first time a MAP violation notice gets disputed by a retailer who says "that's not even the same product."
DataWeave provides an audit trail: who made the match decision, when, and the specific reasoning. Buyer-facing, enterprise governance.
We provide per-match confidence scores (0–100) with specific reasons — "Brand ✓, Model ✓, Color differs" — plus variant-level comparison on size, material, and pack composition. You set your own thresholds for what counts as exact, similar, or not-a-match.
One Competera user on G2 specifically requested "more detailed statistics regarding the delivered data" — confirming that per-match reasoning wasn't standard. Another user on the same platform noted difficulty making adjustments independently.
The other six tools in our review: match or no match. Sometimes a score. No buyer-facing reasoning documented.
Match reasoning and pair-specific matching rules work together. A confidence score is only as trustworthy as the matching logic that produced it. If the system applies one generic rule set to every catalog, even a 95% score doesn't mean what you think it means — the rules weren't calibrated for your specific products. In this comparison, only one tool combines per-match reasoning with pair-specific matching logic — and explainability overall was the exception, not the norm.
8 Best Product Matching Tools and Services — Compared
How we evaluated
We checked each tool against the same 24-point framework covering matching methodology, accuracy claims and measurement, GTIN-free capability, match reasoning, operational burden, setup time, pricing, trial availability, and real user review evidence.
For every tool, we cross-referenced vendor claims against G2, Capterra, and Trustpilot reviews where available.
One pattern worth noting: G2 ratings in this category reflect customer support and ease-of-use far more than matching quality. Prisync has 400+ reviews and a G2 Leader badge — but the weakest matching methodology and the most matching-related complaints. Price2Spy has 300+ reviews with no matching-specific complaints — though that could reflect a user base with simpler catalogs rather than superior matching. Dealavo has 15 reviews but the best-documented accuracy metric in the category.
If you sorted by star rating, you'd get one answer. Our 24-point framework gives you a different — and more useful — one.
| Dimension | PWS | Prisync | Price2Spy | Priceva | Dealavo | Competera | Intel. Node | DataWeave |
|---|---|---|---|---|---|---|---|---|
| Matching | Filter + deep match + human | Barcode only | 4-tier + ML | Semi-managed | ML + double QA | AI + hybrid | Patented AI | Siamese + BERT + CLIP |
| No-GTIN | Fashion proven | No | Enterprise only | Claimed | Yes | Failures reported | Core design | Core design |
| Accuracy evidence | ~95% initial, ~99% after tuning | No public claim | No matching complaints in 300+ reviews (may reflect simpler user base) | Claims 100%; reviewer flags accuracy | 99.5% dual-class FP/FN in case study | Claims 98–99%; 5 complaints | 99% contractual SLA | 80–90% raw → 95%+ → 99%+ |
| Match reasoning | Scores + reasons | No | No | No | No | No | No | Audit trail |
| Pair-specific rules | Yes (per pair) | No | No | No | No | No | No | No |
| Weekly effort | Very low (30–60 min) | High | Moderate | Moderate | Low | Mostly low | Low | Moderate |
| Setup | 48–72 hours | 14-day trial | 14–30 day trial | Months | Unknown | Weeks+ | <1 week | Unknown |
| Starting price | Per-site quote | $99/mo | ~$79/mo+ | Free Starter | Contact sales | Enterprise | $5K/mo min | Enterprise |
| Trial / pilot | Free 48–72hr pilot | 14-day free | 14–30 day free | Free Starter | None | Demo only | None | None |
Tool-by-Tool: What Each Does, What Users Say, Who It's For
Self-Service Tools — You Operate Matching
These tools give you the software. You configure matching, monitor results, and maintain accuracy. Lowest subscription cost — but your team carries the operational weight.
The most popular mid-market price tracker, and for good reason if your catalog runs on barcodes. Shopify native with one-click import. Matching is strictly barcode-first — without GTINs, you add competitor URLs manually, product by product. No text matching, no image matching, no attribute matching beyond barcodes.
Support is genuinely best-in-class at this price point — 28 G2 mentions praise named reps by name, which is rare for a tool under $400/month. Barcode matching works well when identifiers exist.
But URL maintenance is a recurring pain: five G2 reviews flag it. "Manual effort needed to address missing URLs detracts from overall efficiency" (G2). Users have asked for dead-link alerts since 2019. Seven years later, still not standard.
Scraping failures also draw complaints — "incorrect prices shown" on some sites (G2). And API access costs an extra 20% on top of any plan, which means your data stays locked in the dashboard unless you pay the surcharge.
No confidence scores. No match reasoning. No private label capability. Human review is available — as a paid add-on, unpriced.
The core limitation is structural: barcode-only matching works for products with identifiers, but leaves everything else — fashion, own-brand, unstructured listings — in an unmatched queue that grows faster than most teams can process manually.
Four-tier matching methodology — manual, automatch, quick match, and ML hybrid — backed by an 18-month ML R&D investment documented in a five-part blog series. A dedicated data team handles rebranding and packaging changes proactively.
One notable finding: no matching-specific complaints across 300+ reviews. User complaints exist about scraping accuracy ("incorrect prices scraped due to website changes"), but none question whether the right products were matched. That's worth noting — though it could reflect a user base that skews toward simpler, barcoded catalogs rather than proof that matching works for complex categories. The distinction between scraping errors and matching errors matters — they're different problems with different consequences.
Interface is dated — multiple reviewers note it. You can't self-upload CSV files; one user who outgrew the tool called that "a big deal" (Capterra). ML matching is locked behind Enterprise tier — so the most advanced matching capability isn't available to mid-market buyers who need it most. Automatch add-on costs ~$54/month on top of the base plan.
No per-match reasoning. The methodology is transparent (published blog), but the output is match/no-match without the WHY.
Budget entry point. The free Starter plan is the lowest barrier in this comparison, and Google BigQuery export is unique at this price tier. Repricing automation is praised as a "game-changer" by reviewers. Matching is semi-managed — Priceva's team handles it, buyer specifies parameters. Human verification is standard across all plans, not a paid add-on.
But matching isn't the core product here — price monitoring is. That's not a criticism; it's a positioning reality that affects what you should expect from the matching layer.
Review volume is the lowest in this comparison (~30–40 total). G2 profile has been unmanaged for over a year — which tells you something about where the company's attention is focused. One reviewer flags accuracy fluctuations when source sites change. Setup takes "first months" according to reviewers — the slowest initial value among SaaS tools. No confidence scores, no match reasoning, private label not documented.
The most rigorously documented matching accuracy of any tool here: 99.5% measured across both false positives and false negatives in a named case study. Most tools publish one accuracy number with no methodology. Dealavo publishes the dual-class metric that actually tells you something.
That level of measurement transparency is worth noting. It's how accuracy should be reported in this category — but only one tool does it.
Three-team matching process (developers, tech support, QA) at 75% ML / 25% human. Strongest documented feedback loop — the algorithm explicitly learns from corrections. Category-specific plugins for cosmetics volume units, beverage multipacks, and car parts show depth beyond generic matching. Named customers include Samsung, Decathlon, and Acer.
Review volume is very low (~15–20 total) — the biggest trust barrier for buyers who rely on peer validation. Two of eight Trustpilot reviews flag spam or GDPR-noncompliant emails, which is a 25% negative rate on that platform. No public pricing. No free trial. The March 2025 JTL acquisition introduces genuine uncertainty about roadmap, pricing, and team stability.
Self-service tools put matching in your hands at a low subscription cost. But the operational weight — URL maintenance, verification, exception handling, catalog-change response — lands on your team. The next category shifts that weight to the vendor.
Enterprise Platforms — AI Matches, You Verify
These platforms invest heavily in AI to match at scale. You operate a dashboard to review, verify, and act on results. Stronger technology than self-service tools, but your team still carries the verification and exception-handling work.
Full pricing stack in one contract — matching, monitoring, optimization, and repricing. Enterprise logos include Unilever, Sephora, and Watsons. Category parameterization with packaging unit coefficients is confirmed by a user.
Matching quality draws five independent complaints — the most of any tool in this comparison. "Apparently easy-to-identify items cannot be found despite several runs" (Capterra). Another user describes "a great deal of manual effort" when mapping breaks (Capterra). A third notes difficulty making self-service corrections: "difficult to make adjustments in the account by myself" (G2).
No per-match reasoning — one G2 user specifically requested "more detailed statistics regarding the delivered data" and it wasn't available. Learning curve is steep — four G2 mentions call it "time-consuming" and "complex." Pricing starts at $5K–20K for SMB implementations and $50K–100K for enterprise — three G2 reviewers flag cost.
And here's the detail that matters most: Competera's own published content acknowledges that automatic matching accuracy drops to approximately 30% for some categories.
Thirty percent. On auto-matching. For some categories.
That's worth sitting with. A platform with Unilever on its logo wall acknowledges 30% auto-accuracy for some categories. It validates what we see in every complex catalog: even sophisticated AI needs human review for the hard cases. The question is whose humans — the vendor's or yours.
Most technologically advanced option in this comparison. Patented Similarity Engine with Computer Vision and NLP, trained on 1.2 billion products. The only tool offering a contractual 99% accuracy SLA: false positives capped at 1 per 100, false negatives at 1 per 50. Strongest private label matching — documented for "soft categories" across a 400K+ SKU fashion deployment spanning 23 countries.
Setup under one week per two Capterra users. Strongest logo wall: Walmart, Nestlé, LVMH, Prada, Kroger.
The barrier is entry cost. $5K/month minimum — which means this tool is genuinely inaccessible to most mid-market buyers, regardless of how good the technology is. No free trial — demo and custom proposal only. No Shopify or WooCommerce integration. Two G2 reviewers flag a learning curve. And two ownership changes in twelve months — IPG acquisition December 2024, then Omnicom merger 2025.
No per-match reasoning documented — match TYPE is shown (exact/similar/variant) but not the reasoning behind each specific decision.
Most reviews appear incentivized, which limits independent validation.
Advanced AI architecture: Siamese Networks, BERT embeddings, CLIP multimodal scoring, LLM-based vector databases. Broadest match taxonomy — five types: exact, close variant, substitute, complementary combo, and private label.
And critically: one of only two solutions in this comparison that provides buyer-facing match reasoning. User-Led Match Management gives buyers full audit trails — who made the decision, when, and exactly why. This is enterprise governance applied to product matching.
DataWeave is also the most transparent about accuracy in this entire comparison. They openly state raw AI achieves 80–90%, improving to 95%+ with human refinement and 99%+ over time. Those three numbers aren't contradictory — they're honest about the pipeline. Most tools just pick the highest number and put it on the marketing page. DataWeave shows you the journey. That takes confidence.
No public pricing. No Shopify integration. No free trial.
Budget constraints flagged by a G2 reviewer. Fewer Fortune 500 logos than Intelligence Node. No documented setup timeframe.
Enterprise platforms put sophisticated AI behind matching — but your team still operates the dashboard, reviews edge cases, and handles exceptions when the AI falls short. For teams that want the matched data delivered ready to use — without operating any platform — managed matching shifts the entire workflow to the vendor.
Managed Matching — Decision-Ready Data, Delivered
A different model entirely. Instead of giving you a platform to operate, managed matching delivers verified matched data on schedule. Your team reviews output and makes decisions — the vendor handles everything else: setup, matching, QA, ongoing re-matching as catalogs change, and delivery.
This is our product — and we've built it around a specific belief: buyers don't want a matching algorithm. They want a trustworthy comparable-product set they can use for pricing, repricing, assortment analysis, and MAP enforcement without their team becoming the QA department.
The system classifies every product into one of three explicit states: exact match (identical product, pricing-ready), variant (same product family, different size/color/material — useful but not pricing-comparable), and no match (no valid counterpart found).
That tri-state separation is foundational. Most tools force a binary: matched or not. We keep variants visible but separate from the pricing-ready set, so a size-M sweater at $89 doesn't get averaged with a size-XL at $95 and distort your competitive position.
Every match includes a confidence score (0–100) and specific reasons — "Brand ✓, Model ✓, Color differs." Not just a number. The reasoning behind the decision. You set your own thresholds: ≥92 for exact, 70–91 for similar, below 70 rejected. One of two tools in this comparison (alongside DataWeave) providing per-match reasoning, and the only one offering it within a managed service model.
Pair-specific matching rules — the difference between "mostly right" and "decision-ready." Every catalog pair we match gets its own matching protocol. A rug catalog with 71 size/color combinations per product needs different rules than a cosmetics catalog where pack size determines identity. We build the logic for each pair based on the specific characteristics of both catalogs. You don't configure it — we handle it. This is what makes definitive classification at 99%+ confidence possible: exact match, variant, or not-a-match. No ambiguous middle ground.
What the review workflow looks like. For each source product, the system surfaces multiple candidates with side-by-side comparison — product images, names, prices, and source links visible together. No opening 40 browser tabs. Image zoom for categories where small visual details matter — stitch patterns on bags, sole designs on shoes, label placement on apparel. Clickthrough to the live product page on each side. For unresolved items, the system still shows candidates that were tried — so you understand why a product remained unmatched, not just that it did.
The matching pipeline. When we matched 2,068 fashion products for a luxury marketplace — no GTINs, no barcodes — the pipeline scanned 6.8 million potential product pairs, narrowed to 3,795 candidates by filtering out impossible matches first, then produced 632 exact matches and 182 confirmed variants. The rest were correctly classified as not-a-match or flagged for review.
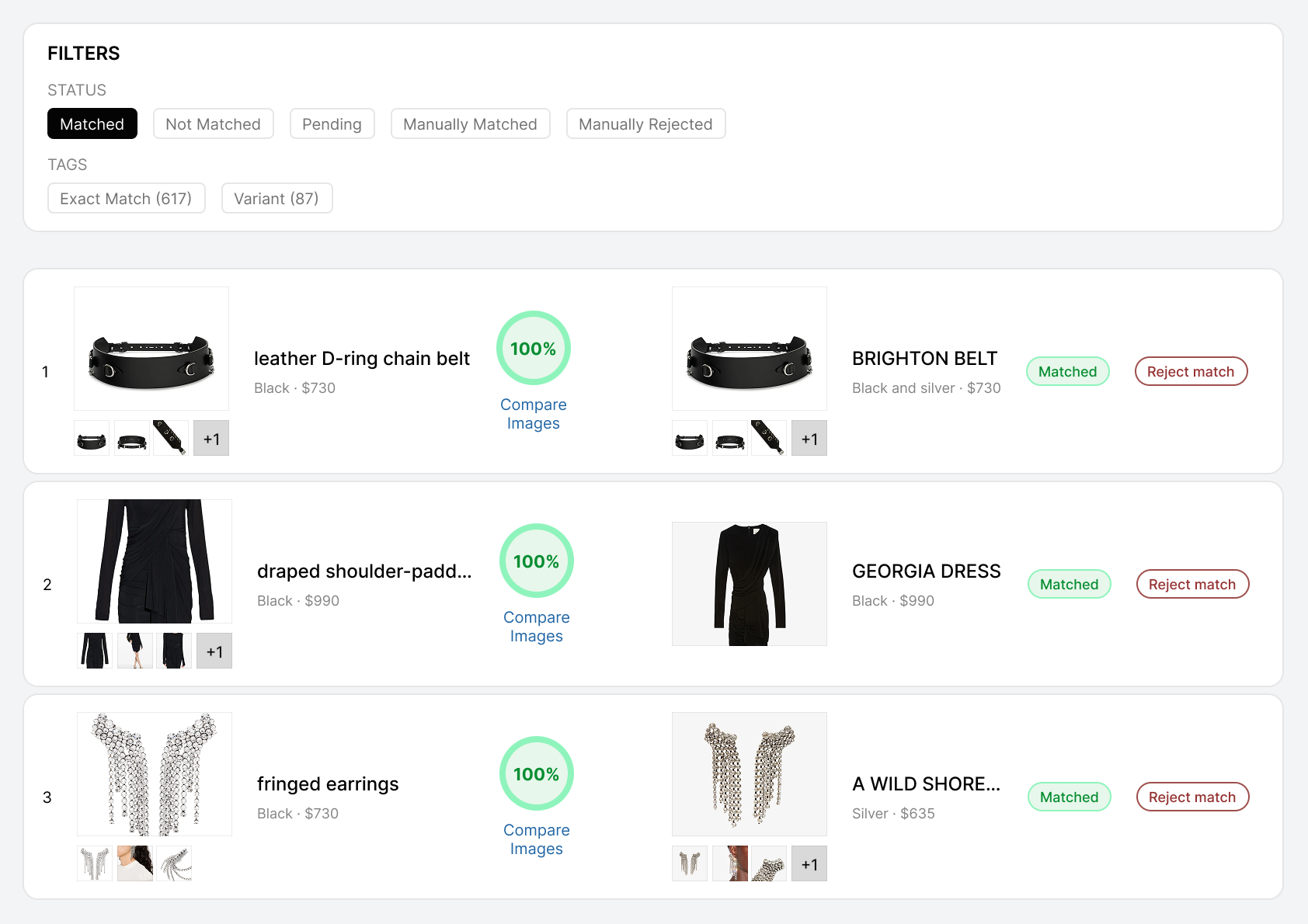
644 near-matches scoring 85–95% confidence were rejected rather than auto-approved. Wrong size variant, wrong colorway, different bundle composition — all caught by deep matching with image comparison after passing text matching.
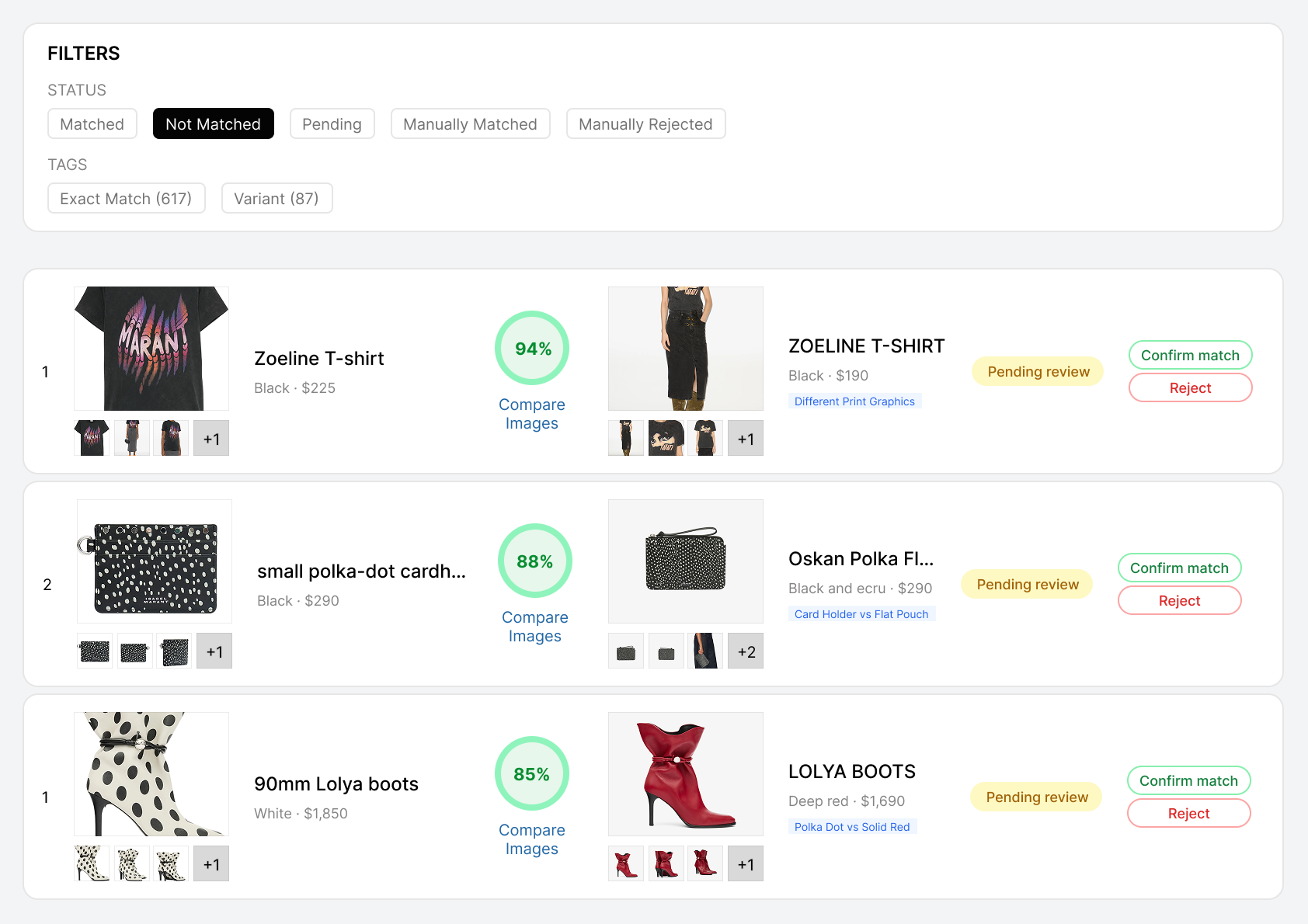
644 rejected near-matches. In a single deployment. That's the gap between "we match products" and "we match products correctly."
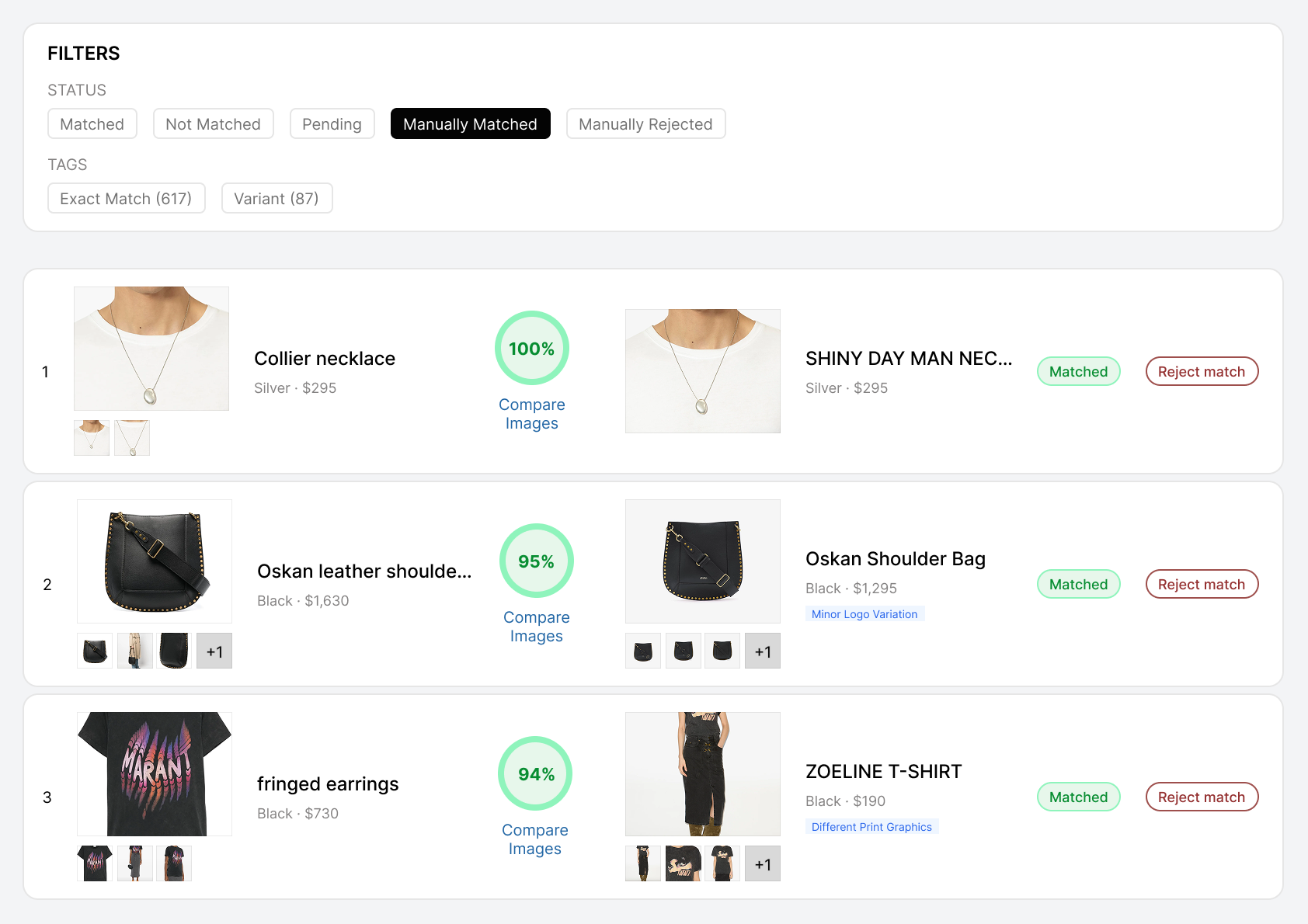
Our three-phase approach: filtering out impossible matches reduces the candidate pool first, then attribute matching runs on survivors, then AI deep matching with image comparison resolves the final shortlist. Human audit catches the remaining edge cases — less than 0.5% of data reaches human review, meaning automation handles 99.5%+ of the decisive work.
What happens when catalogs change. Products get added, discontinued, relabeled. Variant structures shift. We support re-matching over time — your matched product set doesn't go stale because a competitor added a new colorway or restructured their product pages. Manual overrides and corrections feed back into the matching logic, so category-specific adjustments carry forward.
Built for matching — designed to connect. Unlike platforms where matching is one module inside a larger suite, our matching system is purpose-built as a standalone capability. But standalone doesn't mean isolated — matched output feeds directly into pricing workflows, MAP enforcement pipelines, assortment analysis tools, and BI systems. The matched product set becomes the foundation layer that multiple teams use, not data trapped inside one vendor's dashboard.
Output and delivery. Matched pairs delivered via CSV, Excel, Google Sheets, or API — not locked inside a dashboard. S3, BigQuery, Snowflake delivery available. Weekly, monthly, or on-demand. Bulk approve/reject/edit for efficient exception handling at scale. Full audit trail on every decision.
Setup and pricing. 48–72 hours to a full pilot report with 100–300 matched products, confidence scores, and reasons — free. One tuning round included. Per-site pricing means cost doesn't balloon as your catalog grows. Month-to-month, no setup fees. Initial accuracy is approximately 95%, reaching 99% after 2–4 weeks of tuning.
Our matching clients include mid-to-enterprise ecommerce companies across fashion, luxury, electronics, and home goods. Most matching engagements are covered by client confidentiality agreements — the deployment data above is published with client permission, anonymized per their request.
100–300 of your products matched against your competitors in 48–72 hours. Confidence scores and reasons for every match. Free.
Request a Free PilotHow to Evaluate Your Shortlist
You've narrowed to 2–3 options. Here's how to test them before committing.
Pick 10 products weighted for difficulty. Run them through each tool's trial or pilot. Check every match against the live competitor page.
- 4 close variants — similar names, different sizes or colors
- 3 from your highest-traffic competitors
- 3 top sellers your team knows well
How to score: 9–10 correct = decision-ready data. 7–8 = directional, needs ongoing verification. Below 5 = the tool is creating risk, not reducing it.
Five questions for vendor demos
- Show me a match made without a barcode — how do you handle products with no shared identifiers?
- Show me a match your system got wrong — and how it was caught before it reached me.
- Show me WHY this specific match was made — not just a score, but the reasoning behind the decision.
- What does my team actually do every week after setup is complete?
- Do you build matching rules per catalog pair, or use one set of rules for everything?
If the vendor can't answer question 3 — show you the reasoning behind a specific match — that tells you everything about what your team's verification burden will look like.
That one question does more filtering than any feature comparison table.
If you're switching from a current tool
Run both systems on the same 200–500 SKUs for 2–4 weeks before committing. Export your existing match pairs and any custom rules before switching. First-week accuracy isn't final — any new system improves as it learns your catalog's edge cases. And map your current integrations before the switch — the format change is often the hidden migration cost.
The pricing context
McKinsey research published in Harvard Business Review found that a 1% improvement in pricing generates an 8–11% increase in operating profits. Accurate product matching is what makes competitive pricing possible. You can't price against data you can't trust.
Other Tools Worth Knowing About
Minderest — European enterprise platform, particularly strong in Spain and EU markets. Matching capability exists but is lightly documented. Part of several vendor evaluations in our client portfolio.
OptimiX XPA — French pricing suite with AI proximity scoring for product matching. Matching is one module within a broader pricing optimization platform.
Profitero — Enterprise digital shelf analytics, now part of Publicis Groupe. CPG and FMCG focus. Matching is embedded within a larger suite — not offered as a standalone capability.
Frequently Asked Questions
What is product matching in ecommerce?
Product matching connects your products to the same or equivalent products on competitor sites — the foundation for price comparison, MAP monitoring, and assortment analysis. Without accurate matching, competitor data exists but can't be trusted for decisions.
What accuracy should I expect from product matching?
Most tools claim 95–99%. The number means nothing without context. At 95% on 10,000 SKUs, 500 matches are wrong every delivery cycle. Ask vendors: how do you measure accuracy? What counts as a false positive? Does the claim apply to your product categories — or a curated demo dataset?
Can product matching handle private label or own-brand products?
Only some solutions. Private label products share no identifiers with branded equivalents — no GTIN, no shared SKU, no common barcode. Intelligence Node, DataWeave, and ProWebScraper document private label matching capabilities. Most self-service tools cannot handle products without shared identifiers automatically.
How much does product matching cost?
Subscription prices range from free (Priceva Starter) to $5,000+/month (Intelligence Node). But subscription is only part of the cost. Factor in your team's weekly hours verifying, fixing, and maintaining matches. A $99/month tool requiring 8 hours/week of maintenance costs more in total than a managed service with near-zero operational overhead. See our approach to pricing.
Do I need a tool or a service for product matching?
If your team has dedicated resources to operate matching software, verify results, handle exceptions, and respond to catalog changes — a tool works. If you want matched, verified data delivered on schedule with someone accountable for quality — a managed service often delivers lower total cost and higher data trust.
No commitment. Month-to-month if you continue.
Per-site pricing — cost doesn't balloon with catalog size.